
TL;DR
VCF 9 formalizes Private Cloud → Fleet → Instance → Domains and offers two resilience patterns: Fault Domains (Site-HA across zones) for metro continuity within a single instance, and Disaster Recovery (two instances across regions) orchestrated with VMware Live Site Recovery.
Table of Contents
Why VCF 9 Feels Different
VCF 9 clarifies the relationship between Private Clouds, Fleets, and Instances. An Instance contains your Management Domain (SDDC Manager, vCenter, NSX) plus one or more Workload Domains. Fleet services (Operations/Automation) layer on top to unify lifecycle, governance, and provisioning across instances.
Key Concepts
VCF Instance
A complete, self-contained VCF deployment with its own Management Domain and zero or more Workload Domains. This is the unit you operate, upgrade, and (optionally) pair for DR.
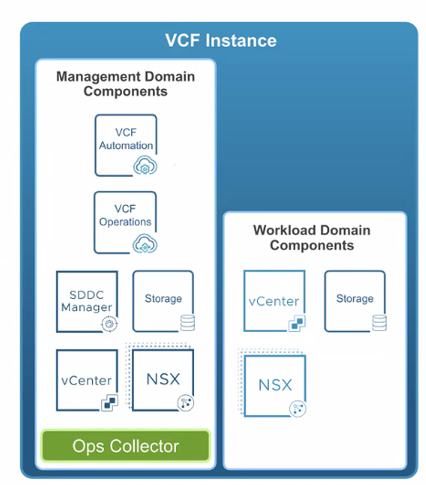
Figure: VCF 9 Instance
VCF Fleet
The centralized management umbrella that groups one or more instances under VCF Operations (lifecycle/health/config) and VCF Automation (provisioning). It standardizes identity, certificates, password policy, tags, and licensing.
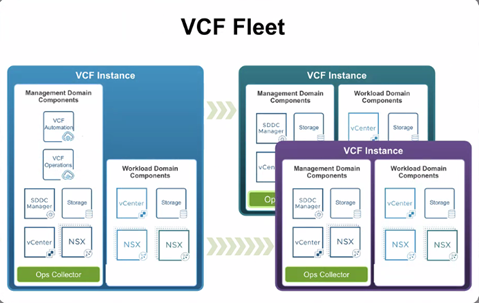
Figure: VCF Fleet
VCF Private Cloud
The top-level construct representing your whole environment—governance, catalogs, networking, and lifecycle—under which you organize Fleets, and inside each Fleet you manage Instances.
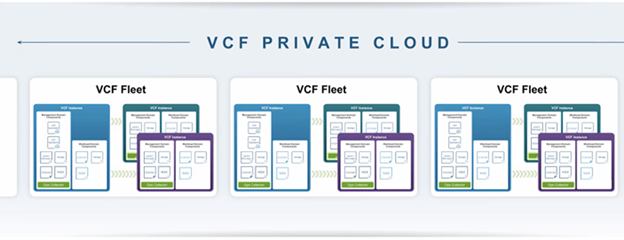
Figure: VCF 9 Private Cloud
Fleet Design Options
There are a few ways you can configure your fleets depending on your needs.
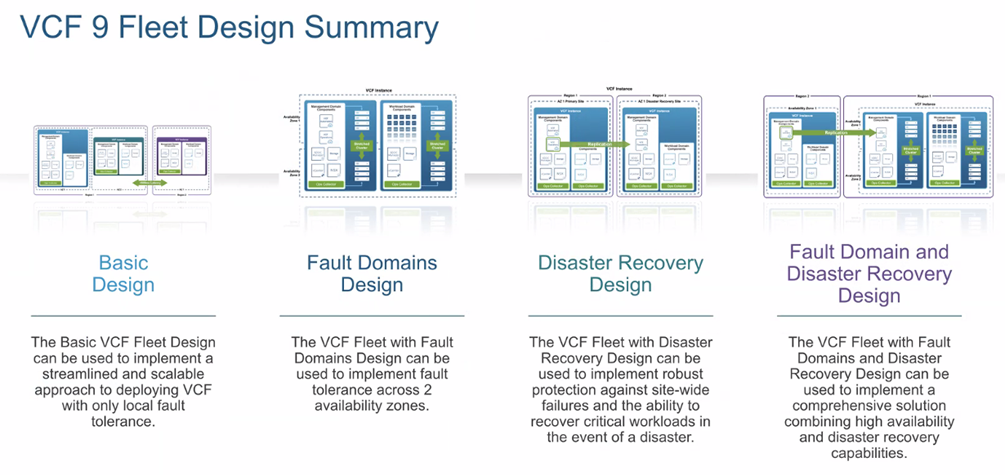
Figure: VCF Fleet Design Summary
Basic Design
Straightforward deployment of Operations/Automation + SDDC Manager. No across-zone or cross-region resilience built in.
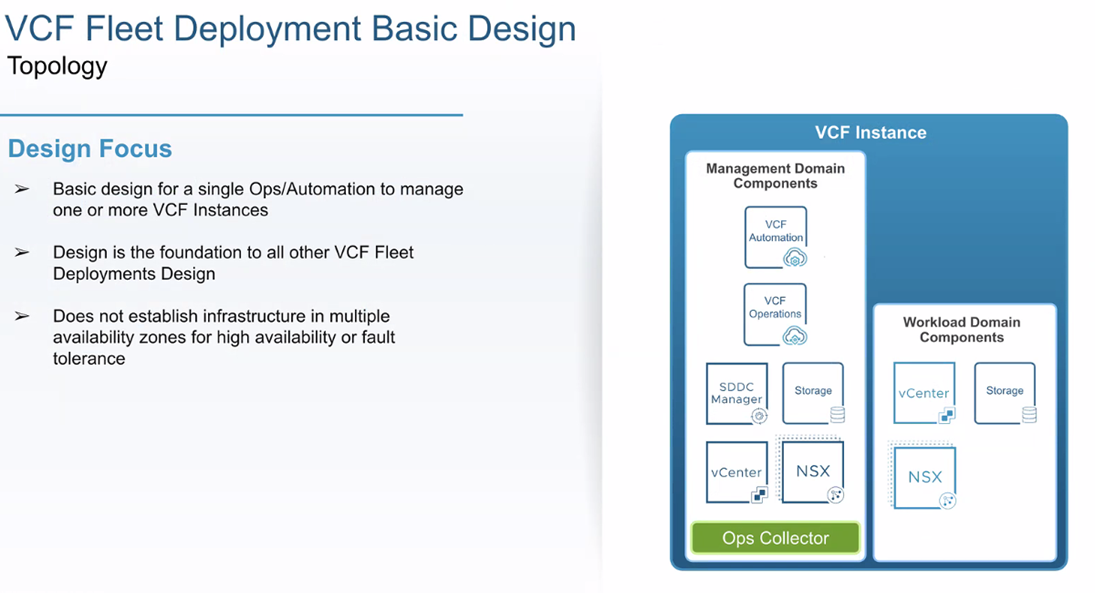
Figure: Example VCF Instance (Basic)
Deployment with Site High Availability (Fault Domains / Across Zones)
Goal: survive an AZ/site failure within a single instance using metro-distance, synchronous storage and IP portability.
- Storage: vSAN stretched clusters (two data sites + witness) or vMSC with synchronous array replication.
- Networking: L2 stretch or NSX/LB approaches for IP continuity.
- Control planes: NSX Manager nodes across zones; VCF Operations/Automation in HA models; place vCenter/SDDC Manager for survivability.
- Typical guardrails: ~≤5 ms RTT between data sites for vSAN; ~≤10 ms RTT host↔array for vMSC (vendor-specific).
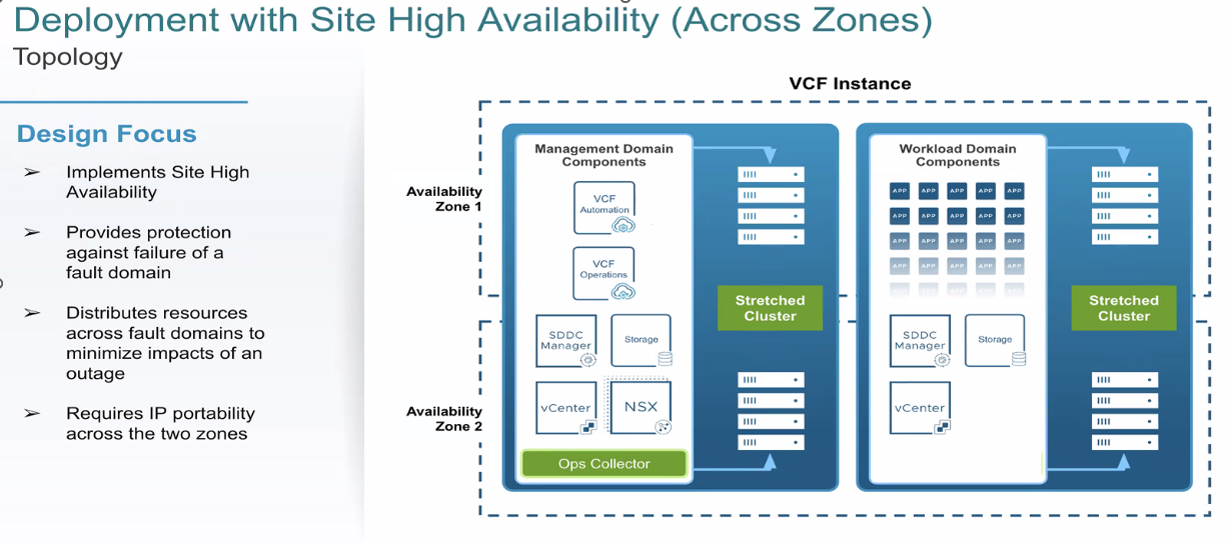
Figure: Site-HA across zones within one VCF instance
Deployment with Disaster Recovery (Across Regions)
Goal: survive a regional event using two VCF instances (Primary/Recovery) and VMware Live Site Recovery (SRM + vSphere Replication and/or array replication). No stretched L2/compute/storage; recovery is orchestrated with Protection Groups and Recovery Plans (boot order, scripts, IP/DNS changes, LB retargets). Some platform services are restored from backup per the validated guidance. Test regularly; document failback.
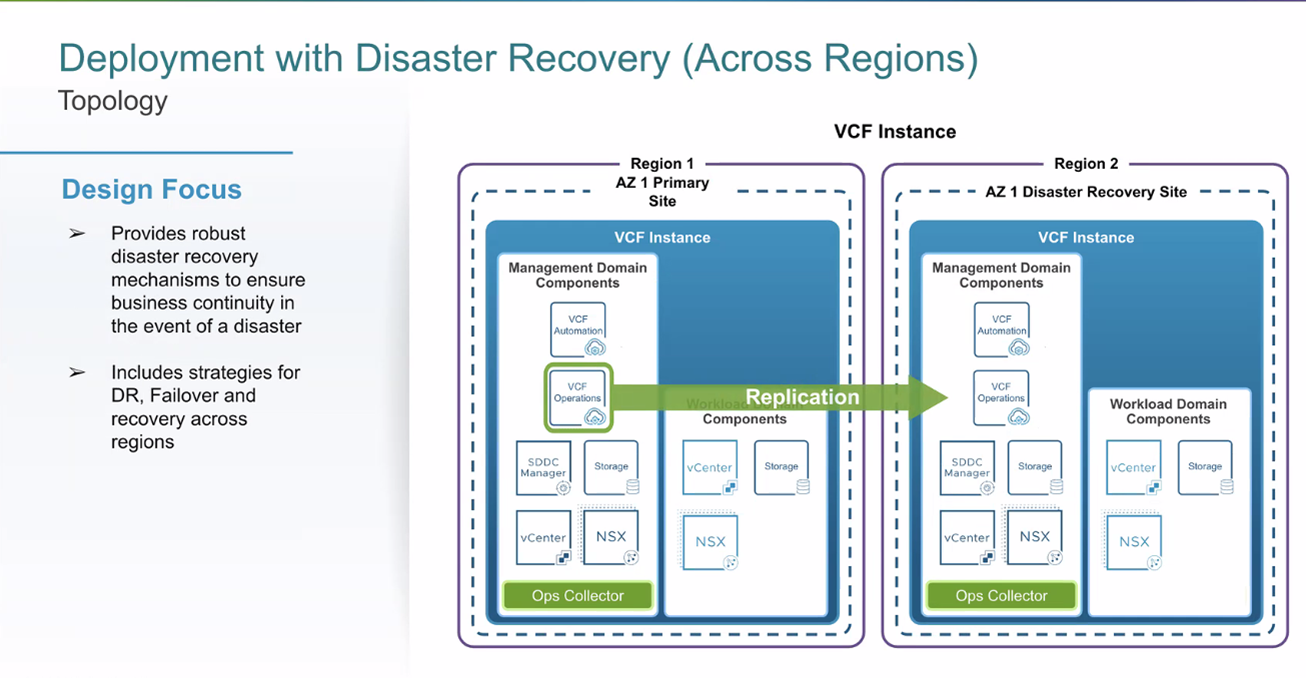
Figure: DR across regions using Live Site Recovery
Combined: Fault Domains + DR
Use Site-HA for AZ failures within a region/instance and DR for regional disasters—a common layered design for enterprise continuity targets.
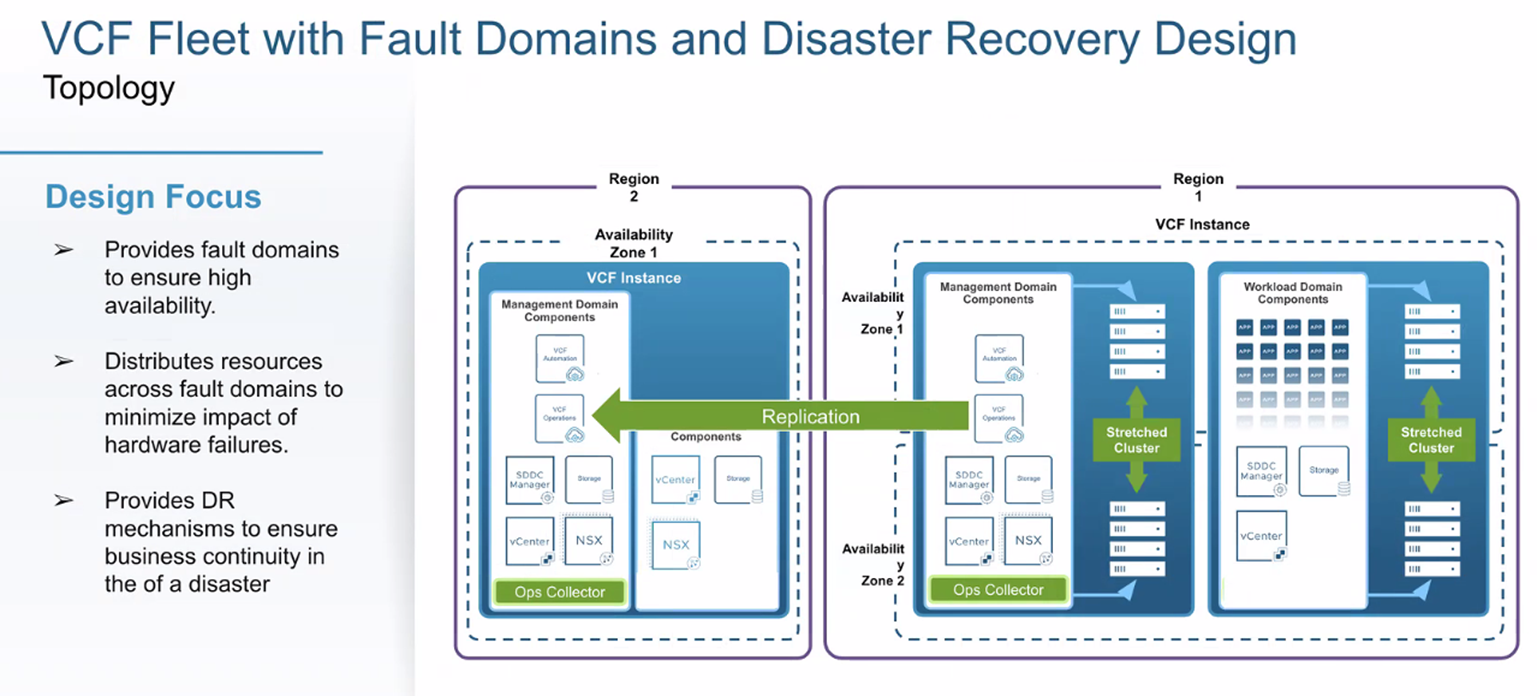
Figure: Fleet with Site-HA (across zones) and DR (across regions)
Reference Links
| Area | What you’ll find | Link |
|---|---|---|
| Validated Solution: DR for VCF 9 | End-to-end design/runbooks for dual-instance DR (what to fail over vs. restore). | Site Protection & Disaster Recovery (VCF 9.x) |
| VCF 9 Docs Hub | Concepts, design library, deployment models. | VMware Cloud Foundation 9.0 Docs |
| Live Site Recovery (SRM + VR) | Install/pair/operate DR stack. | VMware Live Site Recovery 9.0 |
| LSR Release Notes | Compatibility, fixes, features. | 9.0 · 9.0.4 |
| Protection Groups & Plans | How to group VMs and author recovery plans. | SRM: Protection Groups |
| (Contrast) vSAN Stretched | Metro guardrails, witness design. | vSAN Stretched Cluster Guide |
| (Contrast) vMSC Examples | Vendor metro designs / best practices. | NetApp · Dell SRDF/Metro |
💬 Join the Conversation
Have thoughts or questions? Leave a comment below — your insights help others!